From JSON to Parquet using Spark SQL (and HDFS sequence files)
But what does it mean?
The title of this post may sound like gibberish if you are not familiar with the Apache world of "big data" technologies. So let's start with an almost jargon free explanation of what we're going to do and a glossary.
We are going to query text files containing JSON objects as if they were a database table and show the results as charts. To do this efficiently we will then convert the text files to a more table-like file format.
- Spark is a data processing framework.
- Spark SQL is a library built on Spark which implements the SQL query language.
- The HDFS sequence file format from the Hadoop filesystem consists of a sequence of records.
- Parquet is a column-oriented file format that supports compression. Being column-oriented means that instead of storing each row sequentially we store each column separately.
- Zeppelin is a web-based tool for data visualization and collaboration. We will use Zeppelin to run Scala with Spark (including Spark SQL) and create charts.
- Kafka is a platform for distributed, ordered logs, or topics. Not important for understanding the rest of this article, but a fantastic piece of technology that will likely be discussed in another post.
All the above are either full Apache projects or trying to become such
by going through a stage known as "incubating." To get started with Zeppelin
you just download it from the web page, unpack it, run ./bin/zeppelin.sh
and visit http://localhost:8080.
HDFS sequence files
I have some HDFS sequence files in a directory, where the value of each record in the files is a JSON string. In this case they have been created by Secor which is used to back up Kafka topics. The files contain about 14 million records from the NYC taxi data set. Their combined size is 4165 MB and we want to use Spark SQL in Zeppelin to allow anyone who knows SQL to run queries on the files and easily visualize the results.
To do this we will need to convert the HDFS sequence files into a string RDD (resilient distributed dataset, an important construct in Spark) which is used to create a DataFrame. A DataFrame is a table where each column has a type, and the DataFrame can be queried from Spark SQL as a temporary view/table.
Fortunately there is support both for reading a directory of HDFS sequence files by specifying wildcards in the path, and for creating a DataFrame from JSON strings in an RDD.
A slightly tricky detail is the need to use copyBytes in order to get a
serializable type. This is required because the record values have the type
BytesWritable which is not serializable.
Just creating the view takes a while (slightly less than a minute on my computer) because Spark SQL looks at the JSON strings to figure out an appropriate schema.
import org.apache.hadoop.io._
val paths = "file:///home/wjoel/seq/*/*"
val seqs = sc.sequenceFile[LongWritable, BytesWritable](paths)
.map((record: (LongWritable, BytesWritable)) =>
new String(record._2.copyBytes(), "utf-8"))
val df = sqlContext.read.json(seqs)
df.createOrReplaceTempView("trips")
This table, or view, already has a schema that has been inferred from the contents. All columns have the type "string" but we'll change this later.
df.printSchema()
root
|-- dropoff_datetime: string (nullable = true)
|-- dropoff_latitude: string (nullable = true)
|-- dropoff_longitude: string (nullable = true)
|-- hack_license: string (nullable = true)
|-- medallion: string (nullable = true)
|-- passenger_count: string (nullable = true)
|-- pickup_datetime: string (nullable = true)
|-- pickup_latitude: string (nullable = true)
|-- pickup_longitude: string (nullable = true)
|-- rate_code: string (nullable = true)
|-- store_and_fwd_flag: string (nullable = true)
|-- trip_distance: string (nullable = true)
|-- trip_time_in_secs: string (nullable = true)
|-- vendor_id: string (nullable = true)
This is already useful, but the performance is not necessarily good enough for exploratory use cases. Just counting the rows takes a bit more a minute.
SELECT COUNT(*) FROM trips
14,776,615
We can make another query to calculate the average trip distance based on the number of passengers. The data includes some trips with "255" passengers, which is most likely "-1" or "unknown" number of passengers, so we only consider trips with fewer than 50 passengers. Calculating this takes about a minute and a half.
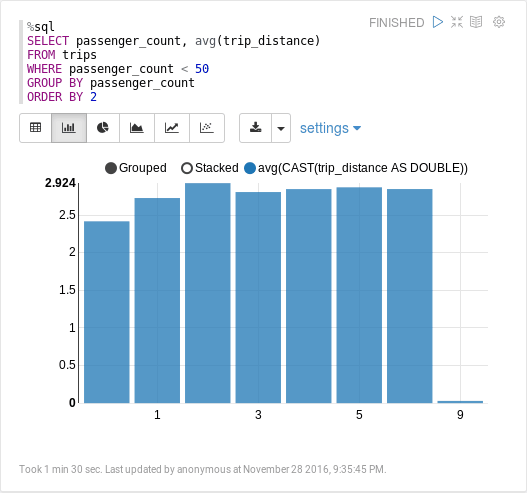
Caching and Parquet
The main reason for the performance issues is the conversion from JSON and, to a lesser extent, the fact that all columns in our DataFrame will be strings. Most of the columns are actually numerical, so strings will be converted to doubles (or longs) again and again when running queries involving means, averages, etc.
If we have enough memory available we can use df.persist(StorageLevel.MEMORY_ONLY)
(cache() is just an alias for persist(StorageLevel.MEMORY_ONLY))
to avoid reading the files and converting from JSON for each query.
The first time we do the row count it actually takes longer, since there's extra work that needs to be done in order to do the caching in memory, but if we make the same query for the count again it takes less than a second. Calculating the average trip distance only takes 3 seconds.
In short, caching has improved the performance dramatically at the cost of some
memory. In fact, we need to configure Zeppelin to actually have enough memory
available for Spark to cache the whole RDD, since it needs 1670 MB and by default
we only have 400 MB (spark.driver.memory * spark.storage.memoryFraction)
available for storage.
We need to add the following to conf/zeppelin-env.sh to have 2.1 GB available
for storage.
export ZEPPELIN_INTP_MEM="-Xms4g -Xmx4g"
Visit http://localhost:4040/executors/ after running some code block in Zeppelin to see how many executors you have running (there should be one, with executor ID "driver") and the amount of storage memory per executor. Then go to http://localhost:4040/storage/ to see the RDDs, and what percentage of them, that are cached.
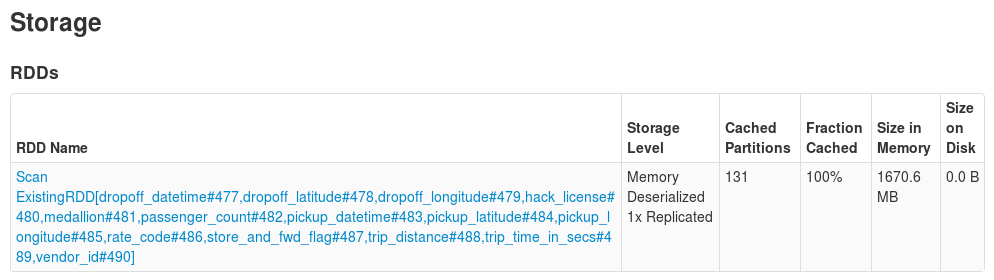
You may be wondering why there's an RDD at all if we're using DataFrames. The reason is that DataFrames are built on top of RDDs, and our table (or view) is "backed" by this RDD.
As if the configuration hassles weren't bad enough the performance can become
unpredictable if there's a shortage of memory, since Spark
can and will evict persisted RDDs from memory if necessary.
If that happens we may end up reading all the files and parsing all the JSON
again. As a compromise we could use StorageLevel.MEMORY_AND_DISK, but then
we would not get the same performance improvements and all columns would still
be of type "string."
It would be better if we could use a columnar data format with types. Parquet is one such format. We will create a Parquet file from our DataFrame. We get several benefits from using Parquet:
- There will be no need to parse JSON strings since it's a binary format. We can still use caching, but if and when it's necessary to read the data from disk it will be much faster.
- The data can be queried more efficiently because the format is based on columns, so there's no need to look around in a JSON structure to find a field, and columns that are irrelevant to the query can be skipped entirely.
- Aggregations which need to scan all values in a column can be done much more efficiently because there is no need for disk seeks and the column data is read sequentially, which is very cache friendly for CPUs.
- The data will be much smaller because Parquet supports compression. Compression is very helpful since some of our data consists of strings with a lot of repetition, like the names of the two taxi companies.
Writing a Parquet file
Writing a DataFrame to a Parquet file is trivial. Using SaveMode.Overwrite
is optional, but was helpful as I was trying different things.
import org.apache.spark.sql.SaveMode
df.write.mode(SaveMode.Overwrite).parquet("/home/wjoel/z/trips.parquet")
You can probably guess how we can create a DataFrame backed by (an RDD backed by) the Parquet file, which is 462 MB.
val parquetDf = sqlContext.read.parquet("file:///home/wjoel/z/trips.parquet")
parquetDf.createOrReplaceTempView("trips_parquet")
Counting the rows only takes an instant, but it takes 40 seconds to calculate the average trip distance. This is still not good enough for data exploration, at least not if we value the explorer's time. Caching can of course still be used but it requires about as much memory as before, since the data Spark needs to store is still a whole RDD of strings, but at least reading it back from disk after being evicted from memory will be faster.
Can we do better? Yes, of course we can. That was a rhetorical question.
Creating a typed schema
We will end this post by creating a proper schema for our DataFrame, because so far all columns are still strings even with Parquet. The performance is already good if we just use Parquet files, but it will be even better after we convert the columns into proper types before saving the Parquet file. Using proper types also saves us some additional disk space. To do this we will invariably have to know something about our data.
Ideally the types would be included in the messages themselves, for example by using Avro. Since we only have JSON we will create the schema explicitly and supply type information for all 14 columns.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
val schemaDf = parquetDf
.withColumn("dropoff_datetime", parquetDf("dropoff_datetime").cast(TimestampType))
.withColumn("dropoff_latitude", parquetDf("dropoff_latitude").cast(DoubleType))
.withColumn("dropoff_longitude", parquetDf("dropoff_longitude").cast(DoubleType))
.withColumn("hack_license", parquetDf("hack_license").cast(StringType))
.withColumn("medallion", parquetDf("medallion").cast(StringType))
.withColumn("passenger_count", parquetDf("passenger_count").cast(LongType))
.withColumn("pickup_datetime", parquetDf("pickup_datetime").cast(TimestampType))
.withColumn("pickup_latitude", parquetDf("pickup_latitude").cast(DoubleType))
.withColumn("pickup_longitude", parquetDf("pickup_longitude").cast(DoubleType))
.withColumn("rate_code", parquetDf("rate_code").cast(LongType))
.withColumn("store_and_fwd_flag", parquetDf("store_and_fwd_flag").cast(StringType))
.withColumn("trip_distance", parquetDf("trip_distance").cast(DoubleType))
.withColumn("trip_time_in_secs", parquetDf("trip_time_in_secs").cast(LongType))
.withColumn("vendor_id", parquetDf("vendor_id").cast(StringType))
schemaDf.createOrReplaceTempView("trips_parquet_schema_added")
We can print the schema to verify that it's using the types we specified and save this as another Parquet file.
schemaDf.printSchema()
schemaDf.write.parquet("/home/wjoel/z/trips_schema.parquet")
root
|-- dropoff_datetime: timestamp (nullable = true)
|-- dropoff_latitude: double (nullable = true)
|-- dropoff_longitude: double (nullable = true)
|-- hack_license: string (nullable = true)
|-- medallion: string (nullable = true)
|-- passenger_count: long (nullable = true)
|-- pickup_datetime: timestamp (nullable = true)
|-- pickup_latitude: double (nullable = true)
|-- pickup_longitude: double (nullable = true)
|-- rate_code: long (nullable = true)
|-- store_and_fwd_flag: string (nullable = true)
|-- trip_distance: double (nullable = true)
|-- trip_time_in_secs: long (nullable = true)
|-- vendor_id: string (nullable = true)
The schema makes a difference. Our original data set was 4165 MB, while this Parquet file with an all strings "schema" is 462 MB and the Parquet file with a schema is 398 MB. Note that both of those files are actually smaller than the cached RDD, which was 1670 MB. Now let's read this back and make a third view.
val schemaParquetDf = sqlContext.read.parquet("/home/wjoel/z/trips_schema.parquet")
schemaParquetDf.createOrReplaceTempView("trips_schema_parquet")
It only takes 1 second to calculate the average trip distance. Again, we're not even caching this. It's fast because the trip distance column is stored as a separate file on disk, and the trip distances are stored as doubles and compressed. Reading that back and calculating the average is trivial compared to parsing JSON, and much faster than reading back strings and parsing them as doubles which is what needs to be done with the "all columns are strings" Parquet file.
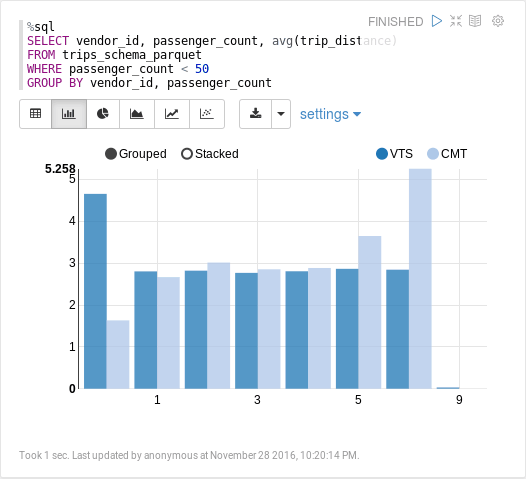
Summary and getting the data
We started out with queries taking about 45 seconds. Data that was 4165 MB. With some memory tricks and parameter tweaking we reduced the query time to 3 seconds, but only if our memory isn't allocated to caching something else. By using Parquet with a schema we ended up with queries taking 1 second and 398 MB data.
Types are important and Parquet is fantastic. JSON is used all over in the real world but converting it to Parquet is easy with Spark SQL. It takes some more effort to create a schema, but it doesn't have to if you use a format like Avro instead of JSON, and it may not be so bad even with just JSON.
Keep in mind that you can choose to specify types only for the
specific fields you care about. For the examples in this post
only specifying the types of vendor_id, passenger_count, and trip_distance
would have given us most of the benefits.
To try this out on a smaller scale you can download a 10 MB or 200 MB HDFS sequence file and use this Zeppelin notebook at home.
If you want more you need to download some files from the NYC Taxi Trips data set, download Kafka and start a local Kafka broker (with ZooKeeper), and download and configure Secor. To use Secor you need to have access to Amazon S3, Azure blob storage, Google Cloud Storage or Openstack Swift. You might be able to make it work with Minio if you don't have a cloud computing account
After configuring Secor to use S3 you can use csv-to-kafka-json to post a CSV file from the taxi trips data set to Kafka, and after a short while you can find the HDFS sequence files created by Secor in your S3 bucket.
I'll have more to say about the visualizations in Zeppelin in the next post. It will be more advanced than this one, so stay tuned if this was too basic for you.